The Brane SDK provides excellent support for GPU acceleration through AMD’s HIP (Heterogeneous-Computing Interface for Portability). This guide will walk you through creating a matrix multiplication application with HIP using the Brane SDK.
Why Use HIP with the Brane SDK? #
AMD HIP offers two key advantages:
- Cross-vendor portability: Code written in HIP can run on both AMD GPUs and NVIDIA GPUs
- Performance: GPUs provide massive parallelism ideal for data-intensive computations
The Brane SDK simplifies HIP development by handling complex build configurations, allowing you to focus on your application code.
Project Structure for HIP Applications #
A HIP-based project in the Brane SDK follows this structure:
matrix-multiply/
├── build.gradle # Project build configuration
└── src/
└── hip/
└── cpp/
└── main.cpp # HIP source code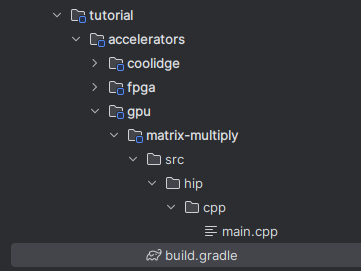
This organization tells the Brane SDK build system where to find your HIP code.
Note: If you’ve completed the “Building Your First Brane SDK Project” tutorial in the previous section, you can use the same approach to create this project structure. The key difference is that you’ll use a different plugin in the
build.gradlefile and place your source code in thesrc/hip/cppdirectory instead ofsrc/main/c.
Setting Up Your First HIP Project #
1. Configure the Build File #
Add the following to your build.gradle file:
plugins {
id 'com.brane.accelerator.gpu.hip.cpp-application' // Plugin for HIP-based C++ applications
}
application {
// Define the target machines for this application
targetMachines = [machines.linux.x86_64, machines.windows.x86_64]
}This configuration:
- Applies the Brane HIP plugin, which sets up all necessary compiler settings
- Targets both Linux and Windows platforms
- Automatically detects and configures the HIP runtime environment
2. Implement the Matrix Multiplication #
Copy the following code into src/hip/cpp/main.cpp:
/*
* Copyright 2025 Brane Technologies
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at:
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include <hip/hip_runtime.h>
#include <iostream>
#include <vector>
#define BLOCK_SIZE 16
/**
* HIP kernel for matrix multiplication.
* Computes C = A * B, assuming square matrices of size NxN.
*
* @param A Pointer to the input matrix A (device memory).
* @param B Pointer to the input matrix B (device memory).
* @param C Pointer to the output matrix C (device memory).
* @param N The dimension of the square matrices.
*/
__global__ void matrixMultiplyKernel(float* A, float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
/**
* Host function to perform matrix multiplication on a HIP-supported GPU.
*
* @param A Host-side input matrix A.
* @param B Host-side input matrix B.
* @param C Host-side output matrix C.
* @param N Size of the matrices (NxN).
*/
void matrixMultiply(const std::vector<float>& A, const std::vector<float>& B, std::vector<float>& C, int N) {
float *d_A, *d_B, *d_C;
// Allocate memory on the GPU
hipMalloc(&d_A, N * N * sizeof(float));
hipMalloc(&d_B, N * N * sizeof(float));
hipMalloc(&d_C, N * N * sizeof(float));
// Copy data to the device
hipMemcpy(d_A, A.data(), N * N * sizeof(float), hipMemcpyHostToDevice);
hipMemcpy(d_B, B.data(), N * N * sizeof(float), hipMemcpyHostToDevice);
// Define block and grid sizes
dim3 blockSize(BLOCK_SIZE, BLOCK_SIZE);
dim3 gridSize((N + BLOCK_SIZE - 1) / BLOCK_SIZE, (N + BLOCK_SIZE - 1) / BLOCK_SIZE);
// Launch the kernel
hipLaunchKernelGGL(matrixMultiplyKernel, gridSize, blockSize, 0, 0, d_A, d_B, d_C, N);
// Copy result back to the host
hipMemcpy(C.data(), d_C, N * N * sizeof(float), hipMemcpyDeviceToHost);
// Free GPU memory
hipFree(d_A);
hipFree(d_B);
hipFree(d_C);
}
/**
* Main function that initializes data, runs matrix multiplication, and prints the result.
*/
int main() {
int N = 4;
std::vector<float> A(N * N, 1.0f);
std::vector<float> B(N * N, 1.0f);
std::vector<float> C(N * N, 0.0f);
matrixMultiply(A, B, C, N);
// Print the result matrix
std::cout << "Result matrix: " << std::endl;
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
std::cout << C[i * N + j] << " ";
}
std::cout << std::endl;
}
return 0;
}Building and Running the Application #
With the Brane SDK, building HIP applications is straightforward:
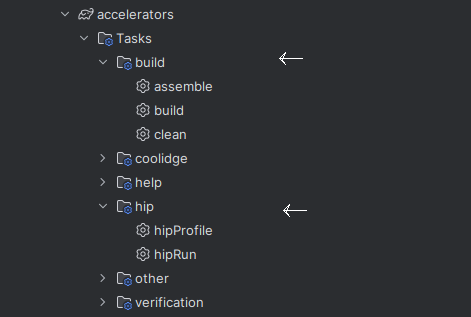
1. Compiling the Application #
- Open the project in IntelliJ IDEA
- Navigate to the Gradle panel
- Expand Tasks > build
- Double-click on “assemble”
2. Running the Application #
After building, you can run the application:
./build/build/exe/hip/bin/hip-matrix-multiply.out 
3. Expected output: #
Result matrix:
4 4 4 4
4 4 4 4
4 4 4 4
4 4 4 4Each value is 4 because we multiply 4×4 matrices filled with 1’s, so each result element is the sum of 4 multiplications: 1×1 + 1×1 + 1×1 + 1×1 = 4.
Understanding the Key Components #
Let’s break down the essential parts of this example:
1. The HIP Kernel #
__global__ void matrixMultiplyKernel(float* A, float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}The kernel:
- Is marked with
__global__to indicate it runs on the GPU - Uses built-in variables (
blockIdx,blockDim,threadIdx) to identify each thread’s position - Computes a single element of the result matrix C
- Includes boundary checks to handle cases where grid dimensions don’t perfectly match matrix dimensions
2. The Host Function #
void matrixMultiply(const std::vector<float>& A, const std::vector<float>& B, std::vector<float>& C, int N) {
float *d_A, *d_B, *d_C;
// Allocate memory on the GPU
hipMalloc(&d_A, N * N * sizeof(float));
hipMalloc(&d_B, N * N * sizeof(float));
hipMalloc(&d_C, N * N * sizeof(float));
// Copy data to the device
hipMemcpy(d_A, A.data(), N * N * sizeof(float), hipMemcpyHostToDevice);
hipMemcpy(d_B, B.data(), N * N * sizeof(float), hipMemcpyHostToDevice);
// Define block and grid sizes
dim3 blockSize(BLOCK_SIZE, BLOCK_SIZE);
dim3 gridSize((N + BLOCK_SIZE - 1) / BLOCK_SIZE, (N + BLOCK_SIZE - 1) / BLOCK_SIZE);
// Launch the kernel
hipLaunchKernelGGL(matrixMultiplyKernel, gridSize, blockSize, 0, 0, d_A, d_B, d_C, N);
// Copy result back to the host
hipMemcpy(C.data(), d_C, N * N * sizeof(float), hipMemcpyDeviceToHost);
// Free GPU memory
hipFree(d_A);
hipFree(d_B);
hipFree(d_C);
}This function follows the standard GPU programming pattern:
- Allocate GPU memory with
hipMalloc - Copy input data to the GPU with
hipMemcpy - Execute the kernel with
hipLaunchKernelGGL - Retrieve results from the GPU with
hipMemcpy - Free GPU memory with
hipFree
The dim3 variables define our thread organization:
blockSize(16, 16)creates blocks of 256 threads arranged in a 16×16 gridgridSizecalculates how many blocks we need to cover the entire matrix
Performance Optimization Tips #
For real-world applications, consider these optimizations:
1. Use Shared Memory #
GPU shared memory is much faster than global memory. For matrix multiplication, load tiles of input matrices into shared memory:
__global__ void optimizedMatrixMultiplyKernel(float* A, float* B, float* C, int N) {
__shared__ float sharedA[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float sharedB[BLOCK_SIZE][BLOCK_SIZE];
// Load data into shared memory tiles
// Compute using the faster shared memory
}2. Implement Error Checking #
For robustness, always check HIP function returns:
hipError_t status = hipMalloc(&d_A, size);
if (status != hipSuccess) {
std::cerr << "hipMalloc failed: " << hipGetErrorString(status) << std::endl;
return false;
}3. Use Asynchronous Operations #
For better performance, overlap computation with data transfers:
hipStream_t stream;
hipStreamCreate(&stream);
hipMemcpyAsync(d_A, A.data(), size, hipMemcpyHostToDevice, stream);
hipLaunchKernelGGL(kernel, grid, block, 0, stream, d_A, d_B);Cross-Platform Targeting #
One of HIP’s key advantages is portability between AMD and NVIDIA GPUs. The Brane SDK simplifies this with target machine specifications:
application {
targetMachines = [
machines.linux.x86_64,
//gpuMachines.amd.default,
gpuMachines.nvidia.default
]
}This configuration generates binaries for both AMD and NVIDIA platforms from a single codebase.
Debugging and Profiling #
The Brane SDK integrates with GPU debugging and profiling tools:
1. Basic Debugging #
1. Add printf statements in your kernel:
__global__ void debugKernel(int* data) {
int i = threadIdx.x;
printf("Thread %d: value = %d\n", i, data[i]);
}2. For more comprehensive debugging:
- Use ROCgdb for AMD GPUs
- Use cuda-gdb for NVIDIA GPUs
2. Performance Analysis #
1. Add printf statements in your kernel:
rocprof --stats ./matrix-multiply 1. Add printf statements in your kernel:
nvprof ./matrix-multiplyCommon Issues and Solutions #
| Issue | Solution |
| Kernel launch failure | Check that grid/block dimensions don’t exceed hardware limits |
| Memory errors | Verify all allocations have corresponding frees and array bounds are respected |
| Poor performance | Consider using shared memory and ensure memory access patterns are coalesced |
| Incorrect results | Double-check array indexing and boundary conditions |
Next Steps #
To further develop your GPU programming skills with the Brane SDK:
- Experiment with larger matrices to see how performance scales
- Implement the shared memory optimization to improve performance
- Try different block sizes to find the optimal configuration for your GPU
- Add error checking to make your code more robust
- Explore other GPU algorithms like image processing or machine learning operations



